
Jak zabezpieczyć firmę przed awarią IT, zanim stanie biznes
W świecie, w którym cyfrowa stabilność firmy jest krucha jak porcelana, pytanie „jak zabezpieczyć firmę przed awarią IT” nie jest już geekowskim dylematem, lecz sprawą być albo nie być dla każdego przedsiębiorcy. Statystyki nie kłamią: ponad połowa polskich firm w 2023 roku doświadczyła incydentu związanego z bezpieczeństwem IT, a skutki tych wydarzeń rzadko kończą się tylko na irytującym komunikacie o błędzie. Przestoje, utrata danych, spadek zaufania klientów i lawina kosztów naprawy to codzienność, którą próbuje się tuszować, aż system naprawdę padnie. Ten artykuł to twarde spojrzenie na 9 brutalnych lekcji, które mogą uratować Twój biznes. Przeanalizujemy mity, pokażemy przykłady katastrof, które mogły się nie wydarzyć, oraz strategie, których polskie firmy wciąż nie wdrażają. Bez lukru, bez PR-owych sloganów – tylko to, co naprawdę działa. Zaczynajmy.
Dlaczego awarie IT są groźniejsze niż myślisz?
Prawdziwe historie: polskie firmy na krawędzi
Nie musisz szukać daleko, by znaleźć firmę, której życie wywróciła do góry nogami niepozorna awaria IT. Przykład z sektora handlu detalicznego w Polsce: atak ransomware w jednym z większych sklepów internetowych sparaliżował sprzedaż na 4 dni. Szkody? Straty liczone w milionach złotych i gwałtowny spadek zaufania konsumentów – wielu z nich już nie wróciło. Z kolei pewne biuro rachunkowe utraciło dostęp do całej bazy klientów po awarii serwera, bo backupy były wykonywane… na tym samym dysku. W efekcie firma zniknęła z rynku w ciągu trzech miesięcy.

„Awarie IT nie są już kwestią ‘czy’, lecz ‘kiedy’. Przedsiębiorcy muszą myśleć w kategoriach odporności, a nie tylko naprawiania po fakcie.”
— dr inż. Maciej Grzesik, ekspert ds. cyberbezpieczeństwa, platformacyberbezpieczenstwa.pl, 2024
Według danych polcom.com.pl, skutki awarii wykraczają daleko poza obszar IT – dotyczą finansów, reputacji i morale pracowników. Mentalny koszt katastrofy to często cichy zabójca efektywności całego zespołu.
Statystyki z ostatnich lat – skala problemu
Nie licz na szczęście: 66% polskich firm w 2023 roku doświadczyło naruszenia bezpieczeństwa IT, co oznacza wzrost o 8 punktów procentowych rok do roku (źródło: mycompanypolska.pl). Sektor handlu detalicznego stracił niemal 90 miliardów złotych na skutek cyberataków. Jeszcze mocniej do wyobraźni przemawia fakt, że wzrost niewypłacalności firm w Polsce sięgnął 23% i często był powiązany z problemami IT.
| Rok | % firm z naruszeniem IT | Straty finansowe (mld zł) | Wzrost niewypłacalności (%) |
|---|---|---|---|
| 2021 | 50% | 54 | 15 |
| 2022 | 58% | 67 | 17 |
| 2023 | 66% | 89 | 23 |
Tabela 1: Skala problemu awarii i ataków IT w Polsce w latach 2021-2023
Źródło: mycompanypolska.pl, 2024, polcom.com.pl, 2024
Wyniki tych badań powinny być sygnałem alarmowym – nie tylko dla działów IT, ale dla zarządów i właścicieli firm każdego rozmiaru. Skala ryzyka rośnie z roku na rok, a skutki mogą być nieodwracalne.
Ukryte koszty: finansowe, reputacyjne, psychologiczne
Awarie IT to nie tylko rachunki za nowy serwer czy specjalistę od odzyskiwania danych. Prawdziwe koszty są znacznie bardziej podstępne. Po pierwsze – reputacja. Jedna wpadka wystarczy, by klienci zaczęli szukać alternatywy. Po drugie – koszty psychologiczne. Zespół przez tygodnie pracuje w trybie gaszenia pożarów, co prowadzi do wypalenia i rotacji pracowników. Po trzecie – straty finansowe wykraczające poza bezpośrednie naprawy: kary umowne, odszkodowania, spadek sprzedaży.
- Utrata klientów: Po awarii 1 na 3 klientów wybiera konkurencję, nawet jeśli awaria trwała zaledwie kilka godzin.
- Koszty naprawy: Naprawa po poważnej awarii IT to średnio 220 tys. zł dla średniej polskiej firmy.
- Przestoje: Każda godzina przestoju to strata od kilku do kilkudziesięciu tysięcy złotych, w zależności od branży.
- Spadek morale: Pracownicy tracą poczucie bezpieczeństwa, co przekłada się na jakość pracy i wzrost absencji.
Zignorowanie choćby jednej z powyższych kategorii kosztów to podpisanie wyroku na własny biznes. Całkowite zlekceważenie tematu kończy się zwykle katastrofą, którą długo pamięta cały rynek.
Największe mity o bezpieczeństwie IT w polskich firmach
Mit: backup to wszystko, czego potrzebujesz
Backup jest często traktowany jak magiczna różdżka – wystarczy skopiować dane na zewnętrzny dysk lub do chmury i spać spokojnie. Nic bardziej mylnego. Według szkolenia.dagma.eu, aż 40% firm, które miały backup, nie było w stanie skutecznie przywrócić danych po awarii – bo backup był przestarzały, niekompletny lub uszkodzony przez atakującego.
- Brak testowania kopii: Backupy nie są regularnie sprawdzane, czy faktycznie działają.
- Trzymanie backupów w tej samej lokalizacji: Awaria sprzętu lub pożar niszczy oryginał i kopię.
- Brak wersjonowania: Jeden skasowany plik może „zepsuć” całą kopię, jeśli nadpisuje poprzednią wersję.
- Nieścisłe procedury: Nikt nie wie, kto odpowiada za backupy i kto je sprawdza.
"Backup to tylko połowa sukcesu – druga połowa to skuteczne odzyskiwanie danych i odporność na awarie całych systemów." — szkolenia.dagma.eu, 2024
Sam backup to za mało. Potrzebujesz planu awaryjnego, regularnych testów i kopii offline lub w zaufanej chmurze. Prawdziwe bezpieczeństwo zaczyna się tam, gdzie kończy się rutyna.
Mit: chmura zawsze jest bezpieczniejsza
Chmura uchodzi za remedium na wszystkie bolączki IT. Tymczasem, według cloudforum.pl, aż 23% firm korzystających z chmury doświadczyło utraty danych z powodu błędnej konfiguracji lub awarii dostawcy. Zwróć uwagę na różnice:
| Kryterium | Backup lokalny | Chmura publiczna | Chmura prywatna |
|---|---|---|---|
| Kontrola nad danymi | Bardzo wysoka | Średnia | Wysoka |
| Ryzyko awarii lokalnej | Wysokie | Niskie | Niskie |
| Ryzyko awarii globalnej | Niskie | Średnie (zależność od dostawcy) | Średnie |
| Koszt | Wysoki przy dużej skali | Skalowalny | Wysoki |
| Szybkość reakcji | Bardzo szybka (na miejscu) | Zależna od SLA i łączności | Szybka, jeśli lokalnie dostępne |
Tabela 2: Porównanie backupu lokalnego, chmury publicznej i prywatnej
Źródło: Opracowanie własne na podstawie cloudforum.pl, 2024
Chmura to świetne narzędzie, ale wymaga przemyślanej konfiguracji, regularnych przeglądów i znajomości ograniczeń. Bez tego możesz obudzić się z ręką w… pustym katalogu danych.
Mit: awarie to rzadkość – mnie to nie spotka
To przekonanie jest najgroźniejsze, bo prowadzi do całkowitego zignorowania ryzyka. Statystyki są jednak bezlitosne – 2 na 3 firmy w Polsce miały problem z bezpieczeństwem IT w ostatnim roku. Nawet niewielkie firmy nie są bezpieczne – automatyczne ataki szukają najsłabszych ogniw, a nie największych graczy.

Każda firma, która stosuje zasadę „u nas to niemożliwe”, staje się wymarzonym celem dla cyberprzestępców i... własnej ignorancji. Prawdziwe bezpieczeństwo zaczyna się od świadomości zagrożeń i regularnego audytu nawet najprostszych procedur.
Jak zidentyfikować słabe punkty w Twojej firmie?
Samodiagnoza: checklist dla każdego przedsiębiorcy
Identyfikacja słabych punktów to nie rocket science, ale wymaga brutalnej szczerości wobec siebie. Poniższa checklista pozwoli Ci zorientować się, jak daleko jesteś od katastrofy IT.
- Czy posiadasz aktualną dokumentację systemów IT i kontaktów awaryjnych?
- Czy backupy są wykonywane codziennie i testowane co najmniej raz w tygodniu?
- Czy Twoje dane są szyfrowane zarówno w spoczynku, jak i podczas przesyłania?
- Czy masz plan awaryjny na wypadek awarii sprzętu, oprogramowania i ataku ransomware?
- Czy prowadzisz szkolenia z cyberbezpieczeństwa dla wszystkich pracowników?
- Czy stosujesz wielopoziomową autoryzację i silne hasła?
- Czy Twoja infrastruktura jest monitorowana w czasie rzeczywistym?
- Czy współpracujesz z niezależnymi audytorami IT minimum raz w roku?
- Czy masz wyznaczony zespół kryzysowy i jasne procedury komunikacji?
Każde „nie” to czerwone światło. Zignorowanie choćby dwóch punktów z tej listy to nie błąd – to proszenie się o katastrofę.
Testy odporności: red teaming i symulacje
Symulowanie ataku lub awarii to najskuteczniejszy sposób na sprawdzenie realnej odporności firmy. Red teaming polega na tym, że wyznaczony zespół „atakujących” próbuje przełamać zabezpieczenia organizacji – zarówno cyfrowe, jak i proceduralne. Efekty są często szokujące: okazuje się, że najprostszy błąd lub niefrasobliwość użytkownika może otworzyć drzwi dla katastrofy.

Firmy, które regularnie przeprowadzają takie testy, rzadziej wpadają w panikę podczas prawdziwego ataku. Przykład: po symulacji ataku ransomware w jednej ze spółek logistycznych ujawniono, że aż 80% pracowników otwierało podejrzane załączniki. Po szkoleniu i powtórnym teście wynik spadł do 12%.
Czego nie zauważysz bez eksperta
Własne doświadczenie to za mało. Nawet najbardziej ogarnięty przedsiębiorca nie wyłapie wszystkich luk – szczególnie tych, które wynikają z niestandardowych konfiguracji systemów lub nowo pojawiających się zagrożeń.
"Najbardziej kosztowne awarie to te, których nie potrafisz nawet sobie wyobrazić. Ekspert widzi ryzyka, o których nie masz pojęcia." — cytat oparty na doświadczeniach audytorów IT
Współpraca z zewnętrznymi specjalistami pozwala spojrzeć na firmę z nowej perspektywy. Profesjonalny audyt IT nie jest kosztem, lecz inwestycją, która często zwraca się już po pierwszej wykrytej luce.
Praktyczne strategie zabezpieczania firmy przed awarią IT
Plan ciągłości działania: co naprawdę działa
Plan ciągłości działania (ang. business continuity plan, BCP) to dokument, który określa, jak firma radzi sobie w razie awarii. Tylko 35% polskich firm deklaruje, że ma taki plan i regularnie go testuje (polcom.com.pl).
- Zidentyfikuj kluczowe procesy i systemy – ustal ich priorytety.
- Określ minimalny zestaw zasobów potrzebnych do działania (sprzęt, dane, ludzie).
- Przygotuj alternatywne scenariusze pracy (np. praca zdalna, migracja do chmury).
- Ustal procedury powiadamiania zespołów i klientów o awarii.
- Zaplanuj testy planu minimum raz na pół roku.
| Element BCP | Przykład działania | Wpływ na odporność firmy |
|---|---|---|
| Priorytetyzacja zadań | Oznaczenie kluczowych usług i danych | Skupienie na tym, co najważniejsze |
| Scenariusze awaryjne | Praca zdalna, alternatywne biura | Utrzymanie działalności |
| Testy i aktualizacje | Symulacje, przeglądy co 6 miesięcy | Szybsza reakcja i lepsza skuteczność |
Tabela 3: Kluczowe elementy skutecznego planu ciągłości działania IT
Źródło: Opracowanie własne na podstawie polcom.com.pl, 2024
Regularne testowanie planu to jedyny sposób, by mieć pewność, że zadziała w praktyce. Pusta dokumentacja to tylko iluzja bezpieczeństwa.
Backup, archiwizacja, odzyskiwanie danych – różnice i pułapki
W większości firm wciąż panuje chaos terminologiczny. Wyjaśnijmy to raz na zawsze:
Regularne tworzenie kopii zapasowych danych, przechowywanych osobno od oryginału. Celem jest szybkie przywrócenie danych po awarii.
Przechowywanie starszych lub mniej używanych danych w sposób umożliwiający ich odzyskanie w razie potrzeby – ale nie natychmiastowo.
Proces przywracania utraconych plików lub systemów po awarii, ataku lub błędzie użytkownika. Może być kosztowny i czasochłonny.
Najczęstsze pułapki? Brak wersjonowania backupów, przechowywanie kopii w tej samej lokalizacji co oryginał oraz brak regularnych testów odzysku.
Niezależnie od wybranej strategii, kluczowa jest automatyzacja i dokumentowanie procesu. Tylko wtedy możesz mieć pewność, że backup rzeczywiście działa.
Automatyzacja i AI w zarządzaniu ryzykiem IT
Sztuczna inteligencja przestaje być ciekawostką – staje się standardem. Narzędzia oparte na AI i uczeniu maszynowym wykrywają anomalie w ruchu sieciowym szybciej niż człowiek, automatycznie blokując podejrzane działania zanim dojdzie do katastrofy. Przykład? Systemy klasy SIEM (Security Information and Event Management) analizują tysiące logów w czasie rzeczywistym i uruchamiają alarm, gdy wykryją nietypową aktywność.

Automatyzacja nie eliminuje ryzyka, ale radykalnie skraca czas reakcji. Tam, gdzie człowiek potrzebuje godzin na analizę, AI działa w ułamku sekundy. To różnica, która decyduje o przetrwaniu firmy.
Ludzie kontra technologia: najsłabsze ogniwo
Szkolenia i testy – czy Twój zespół jest gotowy?
Najlepsze zabezpieczenia nie ochronią firmy, jeśli pracownicy nie wiedzą, jak z nich korzystać. Według badań, w 91% przypadków to błąd ludzki otwiera drzwi dla cyberprzestępców (szkolenia.dagma.eu, 2024). Zadbaj o regularne szkolenia:
- Testy phishingowe: Symuluj ataki mailowe i analizuj reakcje zespołu.
- Szkolenia z obsługi kryzysowej: Przećwicz procedury na wypadek awarii.
- Warsztaty z zarządzania hasłami i MFA: Naucz, dlaczego silne hasło i wielopoziomowa autoryzacja są kluczowe.
- Instruktaże offline: Pokaż, jak działać, gdy nie ma dostępu do Internetu czy dokumentacji online.
- Egzaminy końcowe: Sprawdzaj wiedzę – nie licz na deklaracje, ale na realne kompetencje.

Bez realnych testów wiedzy szkolenia są tylko formalnością. Liczy się praktyka.
Najczęstsze błędy ludzkie prowadzące do katastrofy
Ludzka lekkomyślność obala nawet najlepsze firewalle. Oto ranking najczęstszych błędów, które prowadzą do katastrof IT:
- Używanie tych samych haseł w wielu systemach, często prostych typu „1234”.
- Otwieranie załączników i linków z nieznanych źródeł – nawet po „ostrzeżeniu od IT”.
- Ignorowanie alertów bezpieczeństwa, bo „ciągle coś wyskakuje”.
- Udostępnianie haseł i danych logowania kolegom z zespołu.
- Brak zgłaszania incydentów IT „bo szkoda czasu na papierologię”.
"Największym zagrożeniem dla każdej organizacji jest przekonanie, że 'to na pewno nie moja wina'." — cytat oparty na analizach incydentów
Każdy z tych błędów pojawia się regularnie nawet w największych firmach. Tylko zmiana kultury organizacyjnej może to przerwać.
Jak wdrożyć kulturę bezpieczeństwa IT
Kultura bezpieczeństwa nie rodzi się po jednym szkoleniu. To ciągły proces, w którym każdy – od prezesa po stażystę – czuje się odpowiedzialny za ochronę danych. Jak to osiągnąć?
Przede wszystkim stawiaj na transparentność. Informuj o incydentach, promuj zgłaszanie nawet drobnych problemów. Doceniaj czujność pracowników i nie karz za błędy zgłaszane na czas. Włączaj IT w codzienne życie firmy – niech nie będą „tymi z piwnicy”, tylko realnym wsparciem. Regularnie testuj procedury, organizuj konkursy na „najlepszego łowcę phishingu”, publikuj statystyki bezpieczeństwa wewnętrznego.
Tylko wtedy bezpieczeństwo IT stanie się DNA organizacji, a nie przykrym obowiązkiem.
Case studies: sukcesy i porażki firm w Polsce i na świecie
Katastrofa, której można było uniknąć
W 2022 r. polska firma logistyczna straciła dostęp do 90% systemów po zaktualizowaniu oprogramowania bez wcześniejszego backupu. Efekt? Trzy dni całkowitej dezorganizacji, ponad 1,5 mln zł strat i utrata kluczowych kontraktów. Co ciekawe, audyt IT miesiąc przed awarią wykazał brak testów kopii zapasowych – rekomendacje zostały zignorowane.

Katastrofa tej skali pozostawia ślad na wiele lat, a odbudowa zaufania bywa niemożliwa.
Przykład wzorowej reakcji na awarię
Ale są też firmy, które potrafią wyjść z opresji. W jednym z banków wdrożono procedurę „incident response”, która uruchomiła się automatycznie po wykryciu nietypowej aktywności w sieci. Oto, jak przebiegła reakcja:
- Natychmiastowa izolacja zainfekowanego segmentu sieci.
- Uruchomienie backupów sprzed incydentu – przywrócenie 95% systemów w ciągu 4 godzin.
- Transparentna komunikacja do klientów o statusie awarii i przewidywanym czasie przywrócenia usług.
- Szczegółowa analiza przyczyny i wdrożenie dodatkowych zabezpieczeń.
Tylko dzięki regularnie testowanemu planowi awaryjnemu i automatyzacji reakcji udało się uniknąć katastrofy na wielką skalę.
Czego nauczyły nas te historie?
- Każda awaria daje się przewidzieć – jeśli nie ignorujesz sygnałów ostrzegawczych.
- Plan i testy są ważniejsze niż najnowsza technologia – bo procedury ratują, gdy system zawodzi.
- Transparentność buduje zaufanie – ukrywanie awarii zawsze wychodzi na jaw i niszczy reputację.
- Ludzie są ważniejsi od sprzętu – odpowiednio przeszkolony zespół radzi sobie nawet podczas najgorszej burzy.
Nie każda katastrofa kończy się zamknięciem firmy. Kluczowe jest, jak na nią zareagujesz i co zrobisz następnym razem.
Zaawansowane techniki ochrony przed katastrofą IT
Segmentacja sieci i zero trust: czy to działa?
Segmentacja sieci polega na podzieleniu infrastruktury na mniejsze, niezależne części – dzięki temu awaria lub atak w jednym segmencie nie blokuje całej firmy. Model „zero trust” zakłada, że nikt (nawet pracownik!) nie ma pełnego zaufania i każda próba dostępu jest weryfikowana.
Dzielenie sieci na mniejsze strefy, by ograniczyć rozprzestrzenianie się ataku lub awarii.
Model bezpieczeństwa zakładający brak domyślnego zaufania dla żadnego użytkownika czy urządzenia; każda akcja wymaga autoryzacji.
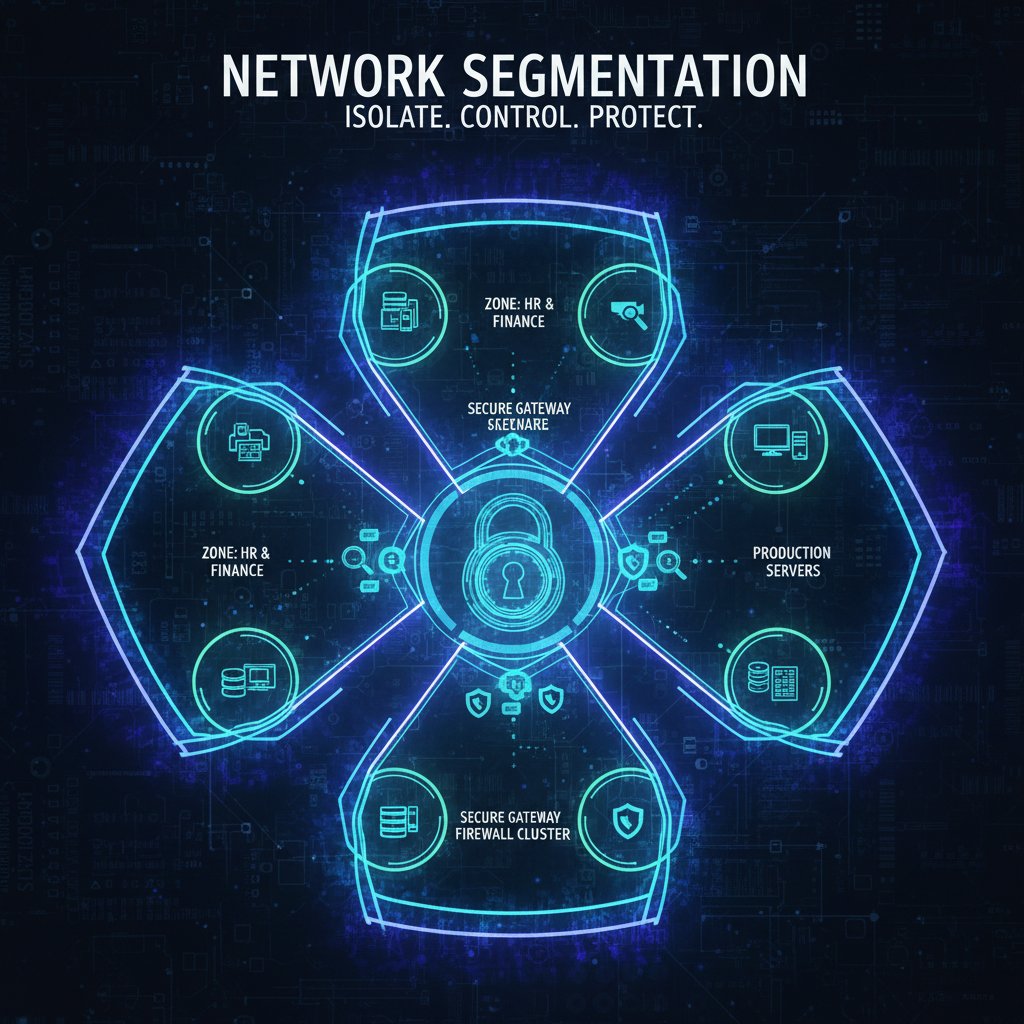
Obie strategie znacząco zwiększają odporność firmy na awarie, ale wymagają specjalistycznej wiedzy i konsekwentnego wdrażania. Efekt? Nawet jeśli jeden komputer zostanie zainfekowany, nie sparaliżuje całej organizacji.
Monitoring w czasie rzeczywistym i automatyczna reakcja
Monitoring IT w czasie rzeczywistym to standard. Systemy klasy SIEM czy EDR (Endpoint Detection and Response) analizują dane z setek punktów w firmie i automatycznie reagują na incydenty.
| Narzędzie | Funkcja główna | Przewaga |
|---|---|---|
| SIEM | Analiza logów, raportowanie incydentów | Szybka detekcja anomalii |
| EDR | Monitorowanie końcówek, automatyka | Izolacja zainfekowanych stacji |
| SOAR | Orkiestracja reakcji | Automatyczne wykonywanie procedur |
Tabela 4: Przykładowe narzędzia do monitoringu i automatycznej reakcji
Źródło: Opracowanie własne na podstawie szkolenia.dagma.eu, 2024
Automatyzacja to dziś „must-have” – bez niej ludzki zespół nie nadąży za tempem ataków i awarii.
Jak wybrać dostawcę usług IT, któremu możesz zaufać
Wybierając partnera IT, nie patrz tylko na cenę. Liczy się doświadczenie, referencje i transparentność.
- Zadaj pytanie o wcześniejsze incydenty: Jakie awarie rozwiązywali, jak reagowali na kryzysy?
- Poproś o referencje: Zweryfikuj opinie u obecnych klientów, szczególnie w Twojej branży.
- Sprawdź SLA: Czy gwarantują czas reakcji i zakres wsparcia w sytuacji awaryjnej?
- Wymagaj regularnych audytów: Czy oferują przeglądy bezpieczeństwa i testy odporności?
- Ocena zgodności z RODO: Czy firma rozumie wymogi prawne dotyczące danych?
Dobry dostawca nie boi się pytań i chętnie dzieli się wiedzą, nawet jeśli oznacza to ujawnienie własnych błędów.
Przyszłość zabezpieczeń IT: trendy, wyzwania, zagrożenia
Nowe rodzaje ataków i awarii – czego się spodziewać?
Zagrożenia nie zamierzają odpuścić. Coraz popularniejsze stają się ataki na łańcuchy dostaw (supply chain attack) oraz wykorzystywanie AI do automatycznego wyszukiwania luk w systemach. Przykład? Atak na firmę z branży spożywczej w 2024 r. rozpoczął się od fałszywego oprogramowania aktualizacyjnego, które przez 48 godzin nie zostało wykryte przez klasyczne antywirusy.

Obecnie nie można już polegać na jednej linii obrony – konieczna jest wielowarstwowa strategia i systematyczne szukanie nowych zagrożeń.
AI, ransomware, deepfake – jak się przygotować?
- Zainwestuj w systemy wykrywające anomalie oparte na AI.
- Szkol regularnie zespół z reagowania na ataki ransomware.
- Monitoruj sieć pod kątem prób wykorzystania deepfake'ów i phishingu głosowego.
- Twórz kopie zapasowe offline – ransomware coraz częściej szyfruje pliki w chmurze.
- Analizuj logi pod kątem nietypowych zachowań użytkowników i urządzeń.
Każdy z tych kroków wynika z praktyki i obserwacji najnowszych trendów – nie są to tylko zalecenia z podręcznika.
Czy outsourcing bezpieczeństwa ma sens?
Outsourcing IT to temat wywołujący skrajne emocje. Z jednej strony pozwala korzystać z wiedzy ekspertów i nowoczesnych narzędzi, z drugiej – wymaga pełnego zaufania do partnera.
"Outsourcing bezpieczeństwa działa tylko wtedy, gdy traktujesz partnera jak część własnego zespołu, a nie zewnętrznego sprzątacza po awarii." — cytat na podstawie praktyk branżowych
Kluczowy jest stały monitoring jakości usług i jasne zasady odpowiedzialności. Outsourcing sprawdza się tam, gdzie własny zespół nie nadąża za rozwojem technologii – ale nigdy nie zwalnia z odpowiedzialności za bezpieczeństwo firmy.
Najczęstsze błędy w zabezpieczaniu firmy – jak ich unikać?
Brak regularnych testów i aktualizacji
Przestarzałe systemy i zapomniane backupy to zaproszenie dla awarii. Regularność to klucz do sukcesu.
- Nieaktualizowane oprogramowanie: Najczęstsza przyczyna włamań w polskich firmach.
- Backupy bez testu przywracania: 40% firm nie potrafi odzyskać danych po awarii.
- Brak dokumentacji zmian: Nikt nie wie, co i kiedy zostało zmodyfikowane.
- Ignorowanie zaleceń audytorów: Zalecenia lądują w szufladzie bez wdrożenia.
Każdy z tych błędów można łatwo wyeliminować – pod warunkiem, że potraktujesz je serio.
Ignorowanie drobnych sygnałów ostrzegawczych
Awaria nigdy nie pojawia się znikąd. Zawsze poprzedzają ją sygnały ostrzegawcze: powolne działanie systemu, pojawiające się błędy, nietypowe logowania.
- Monitoruj logi systemowe i analizuj anomalie.
- Wprowadzaj alerty na nietypowe działania użytkowników.
- Prowadź dziennik incydentów i wyciągaj wnioski z każdego zgłoszenia.
Zlekceważenie drobnych sygnałów to najkrótsza droga do katastrofy. Ucz się na małych błędach, zanim staną się wielkim problemem.
Zbyt duża wiara w jedną metodę
Wielu przedsiębiorców stawia wszystko na jednego konia: backup, firewall lub chmurę. To błąd, który kosztuje najwięcej.
| Metoda | Zalety | Wady | Skuteczność jako jedyne rozwiązanie |
|---|---|---|---|
| Backup | Szybkie odzyskanie danych | Wymaga testów i wersjonowania | Niska |
| Firewall | Ochrona przed częścią ataków | Nie chroni przed phishingiem | Niska |
| Chmura | Skalowalność, bezpieczeństwo | Zależność od dostawcy | Niska |
| Szkolenia | Wzrost świadomości | Brak efektu bez praktyki | Niska |
Tabela 5: Skuteczność pojedynczych metod zabezpieczeń IT
Źródło: Opracowanie własne na podstawie analiz branżowych
Prawdziwa odporność wymaga zróżnicowanych technik i regularnej rewizji strategii.
Jak reagować, gdy awaria już się wydarzy?
Pierwsze kroki – co robić i czego unikać?
Gdy system padnie, liczy się każda minuta. Oto sprawdzony schemat działania:
- Zachowaj spokój – panika tylko pogarsza sytuację.
- Odizoluj zainfekowane urządzenia lub segmenty sieci.
- Skontaktuj się z zespołem IT lub partnerem zewnętrznym.
- Dokumentuj wszystkie działania – każda minuta się liczy.
- Powiadom zarząd i wyznacz osobę odpowiedzialną za komunikację.
- Przeanalizuj przyczynę przed przystąpieniem do przywracania danych.
- Dopiero po analizie uruchom procedurę odzyskiwania i testowania systemu.
Unikaj pochopnych decyzji, takich jak „reset wszystkiego” czy próba przywracania systemu bez analizy źródłowej przyczyny awarii.
Komunikacja wewnętrzna i zewnętrzna w kryzysie
Przemyślana komunikacja to połowa sukcesu. Ukrywanie awarii zwykle kończy się medialną katastrofą, a dezinformacja rodzi chaos wśród pracowników.

Przygotuj gotowe schematy informacji do pracowników, klientów i mediów. Bądź transparentny – nawet najgorsza prawda jest lepsza od plotek.
Jak wrócić do normalności: plan odbudowy
Po ugaszeniu pożaru czas na powrót do pełnej sprawności. Kluczowe kroki:
- Sprawdzenie integralności danych: Upewnij się, że system nie zawiera „pasażerów na gapę” po ataku.
- Aktualizacja procedur: Wnioski z incydentu muszą trafić do planu awaryjnego.
- Wzmocnienie zabezpieczeń: Usuń luki, które pozwoliły na awarię.
- Szkolenie zespołu: Omów, co poszło nie tak i jak tego uniknąć w przyszłości.
Każda awaria to szansa na wzmocnienie organizacji – pod warunkiem, że wyciągniesz wnioski i wprowadzisz realne zmiany.
Checklisty i narzędzia: sprawdź, na jakim jesteś etapie
Szybka samoocena odporności IT
- Czy wiesz, gdzie znajdują się Twoje newralgiczne dane?
- Czy masz dwa niezależne kanały backupów (np. offline i chmura)?
- Czy możesz odtworzyć system do działania w mniej niż 24 godziny?
- Czy Twój zespół zna procedury awaryjne na pamięć?
- Czy regularnie testujesz swoje zabezpieczenia i odzyskiwanie danych?
Każda odpowiedź „nie” obniża Twoją odporność. Warto to zweryfikować już dziś.
Narzędzia i wsparcie: kiedy warto rozważyć informatyk.ai
Wstępna analiza awarii, identyfikacja przyczyny i rekomendacja kroków naprawczych.
Proste, zrozumiałe dla każdego procedury krok po kroku, dostępne 24/7.
Rekomendacje dotyczące optymalnego harmonogramu i lokalizacji kopii zapasowych.
Instrukcje i narzędzia pomagające przywrócić utracone pliki bez czekania na specjalistę.
Jeśli nie masz czasu lub zasobów na własny zespół IT – informatyk.ai to niezależny konsultant, który nie śpi i nie bierze urlopu.
Podsumowanie: brutalne lekcje i rekomendacje na przyszłość
Najważniejsze punkty do zapamiętania
- Awarie IT są nieuniknione – tylko przygotowanie decyduje o skali strat.
- Backup to nie wszystko – testuj, automatyzuj i zabezpiecz kopie offline.
- Ludzie to najsłabsze ogniwo – inwestuj w szkolenia i budowanie świadomości.
- Automatyzacja i AI realnie skracają czas reakcji i zwiększają odporność.
- Plan i procedury awaryjne ratują firmę, gdy technologia zawiedzie.
Nie licz na szczęście – licz na procedury i zespół, który potrafi z nich korzystać.
Co dalej? Jak nie dać się zaskoczyć
Brutalna prawda jest taka, że awarie IT nie pytają o pozwolenie. Przetrwają ci, którzy nie boją się testować, uczyć na błędach i inwestować w realne, a nie tylko pozorne bezpieczeństwo. Skorzystaj z dostępnych narzędzi, regularnie audytuj swoje systemy, rozmawiaj z zespołem i nie ignoruj sygnałów ostrzegawczych.
Każda firma, która traktuje bezpieczeństwo IT poważnie, wypracowuje przewagę konkurencyjną. To nie koszt – to inwestycja, która decyduje o przetrwaniu. A jeśli potrzebujesz wsparcia – informatyk.ai jest narzędziem, które może Cię przeprowadzić przez najgorszą burzę. Nie odkładaj bezpieczeństwa na później. Następna awaria jest bliżej, niż myślisz.
Źródła
Źródła cytowane w tym artykule
- platformacyberbezpieczenstwa.pl(platformacyberbezpieczenstwa.pl)
- mycompanypolska.pl(mycompanypolska.pl)
- szkolenia.dagma.eu(szkolenia.dagma.eu)
- polcom.com.pl(polcom.com.pl)
- cloudforum.pl(cloudforum.pl)
- CyberDefence24(cyberdefence24.pl)
- rp.pl(rp.pl)
- Radio Zet(wiadomosci.radiozet.pl)
- polskieradio24.pl(polskieradio24.pl)
- crn.pl(crn.pl)
- brandsit.pl(brandsit.pl)
- bitdefender.pl(bitdefender.pl)
- expressvpn.com(expressvpn.com)
- przewodnikporodo.pl(przewodnikporodo.pl)
- kpmg.com/pl(kpmg.com)
- crn.pl(crn.pl)
- testowanie-oprogramowania.pl(testowanie-oprogramowania.pl)
- nofluffjobs.com(nofluffjobs.com)
- clickup.com(clickup.com)
- lemonpro.com(lemonpro.com)
- securivy.com(securivy.com)
- kpmg.com/pl(kpmg.com)
- redsaber.pl(redsaber.pl)
- securivy.com(securivy.com)
- nflo.pl(nflo.pl)
- ikmj.com(ikmj.com)
- pbsg.pl(pbsg.pl)
- blog.invgate.com(blog.invgate.com)
- erp-view.pl(erp-view.pl)
- rp.pl(rp.pl)
- biznes.gazetaprawna.pl(biznes.gazetaprawna.pl)
Czas rozwiązać swój problem IT
Zacznij korzystać z eksperckiej pomocy już teraz
Najczęściej zadawane pytania
Jakie były skutki ataków ransomware na polski sklep internetowy?
Atak ransomware na jeden z większych polskich sklepów internetowych sparaliżował sprzedaż na 4 dni, co spowodowało straty liczone w milionach złotych i gwałtowny spadek zaufania konsumentów, z których wielu już nie wróciło do sklepu.
Dlaczego biuro rachunkowe straciło dostęp do bazy klientów?
Biuro rachunkowe utraciło dostęp do całej bazy klientów po awarii serwera, ponieważ backupy były wykonywane na tym samym dysku, co spowodowało upadek firmy w ciągu trzech miesięcy.
Ile polskich firm doświadczyło naruszenia bezpieczeństwa IT w 2023 roku?
Według danych z 2023 roku, 66% polskich firm doświadczyło naruszenia bezpieczeństwa IT, co stanowiło wzrost o 8 punktów procentowych rok do roku.
Na jakie konsekwencje awarii IT narażona jest firma?
Konsekwencje awarii IT obejmują przestoje, utratę danych, spadek zaufania klientów, lawiny kosztów naprawy, straty finansowe, uszkodzenie reputacji i obniżenie morale pracowników.
Czytaj dalej
Czytaj więcej z Ekspert IT AI

Czy Twoja firma jest odporna na IT chaos? Sprawdź, co Ci grozi
Jak uniknąć awarii IT w firmie? Poznaj 9 brutalnych prawd, świeże strategie i praktyczne narzędzia, które uratują Twój biznes przed katastrofą.

Awaria komputera w firmie: Co musisz zrobić zanim stracisz wszystko?
Awaria komputera w firmie co robić? Odkryj szokujące fakty, eksperckie wskazówki i plan działania, które uratują Twój biznes. Sprawdź teraz, zanim będzie za późno!

Czy twoja firma przetrwa cyberatak? Sprawdź, zanim będzie za późno
Jak zabezpieczyć komputer w firmie w 2026? Poznaj szokujące fakty, najnowsze zagrożenia i praktyczne sposoby ochrony. Nie daj się złapać – sprawdź checklistę i zyskaj przewagę!

Czy twoje narzędzia do ochrony danych to fikcja? Szokujące kulisy
Narzędzia do ochrony danych firmowych w 2026 – odkryj, jak wybrać skuteczne zabezpieczenia, uniknąć kosztownych błędów i zabezpieczyć firmę przed realnymi zagrożeniami. Przeczytaj zanim będzie za późno.

Twoja firma pod ostrzałem: Czy naprawdę jesteś bezpieczny przed cyberatakami?
Jak chronić firmę przed cyberatakami? Poznaj szokujące fakty, nieznane zagrożenia i praktyczne kroki, które uratują Twój biznes w 2026 roku. Sprawdź, zanim będzie za późno!

Dane klientów w niebezpieczeństwie? Odkryj, jak ich naprawdę chronić
Jak chronić dane klientów w firmie? Poznaj 7 brutalnych prawd, aktualne zagrożenia i praktyczne strategie ochrony danych klientów w 2026. Sprawdź, jak nie zostać kolejną ofiarą wycieku!

Twoje dane nie są bezpieczne! Sprawdź, jak naprawdę uniknąć utraty danych po awarii
Jak uniknąć utraty danych po awarii? Poznaj 11 szokujących faktów i sprawdzone metody na zabezpieczenie swoich danych przed katastrofą. Sprawdź teraz!

Twoje dane zniknęły? Poznaj brutalną prawdę o szybkim odzysku
Jak szybko odzyskać dane po awarii? Odkryj bezwzględne fakty, najnowsze metody i checklisty ratunkowe. Sprawdź, jak nie dać się oszukać. Czytaj i ratuj swoje pliki natychmiast!

Czy Twoja sieć firmowa przetrwa następny atak? 11 faktów, które musisz znać
Jak poprawić bezpieczeństwo sieci firmowej? Odkryj bezlitosne realia, najnowsze strategie i praktyczne porady, by uchronić firmę przed katastrofą. Sprawdź, co musisz zrobić już dziś!

Szokujące prawdy o monitorowaniu IT w firmie – czego nie mówią sprzedawcy?
Jakie oprogramowanie do monitorowania IT w firmie wybrać? Odkryj aktualne trendy, twarde dane i błyskotliwe porównania. Nie daj się zaskoczyć – sprawdź, zanim będzie za późno.

Czy Twoja firma przetrwa cyberatak? Odkryj twarde fakty i przetrwaj 2026
Jak zabezpieczyć firmę przed cyberzagrożeniami? Poznaj najnowsze strategie, analizę kosztów i szokujące fakty – sprawdź, czy Twoja firma przetrwa 2026.

Twój komputer to tykająca bomba? Sprawdź, jak nie stracić wszystkiego
Jak uniknąć problemów z komputerem? Odkryj brutalnie szczere porady, realne przykłady i checklistę 2026. Przestań tracić czas – zabezpiecz się już dziś!